A00-240 Exam
Validated A00-240 Interactive Bootcamp 2021

Master the A00-240 SAS Certified Statistical Business Analyst Using SAS 9: Regression and Modeling Credential content and be ready for exam day success quickly with this Testking A00-240 answers. We guarantee it!We make it a reality and give you real A00-240 questions in our SAS-Institute A00-240 braindumps.Latest 100% VALID SAS-Institute A00-240 Exam Questions Dumps at below page. You can use our SAS-Institute A00-240 braindumps and pass your exam.
NEW QUESTION 1
A linear model has the following characteristics:
✑ A dependent variable (y)
✑ Three continuous predictor variables (x1-x3)
✑ One categorical predictor variable (c1with 3 levels)
Which SAS program fits this model?
- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer: D
NEW QUESTION 2
Refer to the confusion matrix: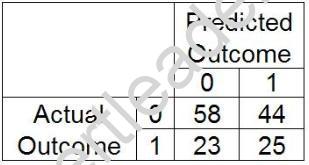
Calculate the sensitivity. (0 - negative outcome, 1 - positive outcome) Click the calculator button to display a calculator if needed.
- A. 25/48
- B. 58/102
- C. 25/B9
- D. 58/81
Answer: A
NEW QUESTION 3
Select the equivalent LOGISTIC procedure model statements. (Choose two.)
- A. Mode1 Purchase * Gender Age Region;
- B. Mode1 Purchase * Gender | Age | Region;
- C. Mode1 Purchase * Gender|Age|Region @1;
- D. Mode1 Purchase * Gender|Age|Region @2;
Answer: AC
NEW QUESTION 4
CORRECT TEXT
A linear model has the following characteristics:
*A dependent variable (y)
*One continuous variable (xl), including a quadratic term (x12)
*One categorical (d with 3 levels) predictor variable and an interaction term (d by x1) How many parameters, including the intercept, are associated with this model?
Enter your numeric answer in the space below. Do not add leading or trailing spaces to your answer.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
7
NEW QUESTION 5
An analyst has a sufficient volume of data to perform a 3-way partition of the data into training, validation, and test sets to perform honest assessment during the model building process.
What is the purpose of the test data set?
- A. To provide a unbiased measure of assessment for the final model.
- B. To compare models and select and fine-tune the final model.
- C. To reduce total sample size to make computations more efficient.
- D. To build the predictive models.
Answer: A
NEW QUESTION 6
A confusion matrix is created for data that were oversampled due to a rare target. What values are not affected by this oversampling?
- A. Sensitivity and PV+
- B. Specificity and PV-
- C. PV+ and PV-
- D. Sensitivity and Specificity
Answer: D
NEW QUESTION 7
Refer to the REG procedure output: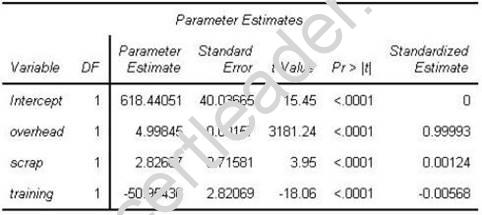
The Intercept estimate is interpreted as:
- A. The predicted value of the response when all the predictors are at their current values.
- B. The predicted value of the response when all predictors are at their means.
- C. The predicted value of the response when all predictors = 0.
- D. The predicted value of the response when all predictors are at their minimum values.
Answer: C
NEW QUESTION 8
Assume a $10 cost for soliciting a non-responder and a $200 profit for soliciting a responder. The logistic regression model gives a probability score named P_R on a SAS data set called VALID. The VALID data set contains the responder variable Pinch, a 1/0 variable coded as 1 for responder. Customers will be solicited when their probability score is more than 0.05.
Which SAS program computes the profit for each customer in the data set VALID?
- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer: A
NEW QUESTION 9
In order to perform honest assessment on a predictive model, what is an acceptable division between training, validation, and testing data?
- A. Training: 50% Validation: 0% Testing: 50%
- B. Training: 100% Validation: 0% Testing: 0%
- C. Training: 0% Validation: 100% Testing: 0%
- D. Training: 50% Validation: 50% Testing: 0%
Answer: D
NEW QUESTION 10
What is a drawback to performing data cleansing (imputation, transformations, etc.) on raw data prior to partitioning the data for honest assessment as opposed to performing the data cleansing after partitioning the data?
- A. It violates assumptions of the model.
- B. It requires extra computational effort and time.
- C. It omits the training (and test) data sets from the benefits of the cleansing methods.
- D. There is no ability to compare the effectiveness of different cleansing methods.
Answer: D
NEW QUESTION 11
Which statistic, calculated from a validation sample, can help decide which model to use for prediction of a binary target variable?
- A. Adjusted R Square
- B. Mallow's Cp
- C. Chi Square
- D. Average Squared Error
Answer: D
NEW QUESTION 12
An analyst knows that the categorical predictor, storeId, is an important predictor of the target.
However, store_Id has too many levels to be a feasible predictor in the model. The analyst
wants to combine stores and treat them as members of the same class level. What are the two most effective ways to address the problem? (Choose two.)
- A. Eliminate store_id as a predictor in the model because it has too many levels to be feasible.
- B. Cluster by using Greenacre's method to combine stores that are similar.
- C. Use subject matter expertise to combine stores that are similar.
- D. Randomly combine the stores into five groups to keep the stochastic variation among the observations intact.
Answer: BC
NEW QUESTION 13
The question will ask you to provide a missing statement. Given the following SAS program:
Which SAS statement will complete the program to correctly score the data set NEW_DATA?
- A. Scoredata data=MYDIR.NEW_DATA out=scores;
- B. Scoredata data=MYDIR.NEW_DATA output=scores;
- C. Scoredata=HYDIR.NEU_DATA output=scores;
- D. Scoredata=MYDIR,NEW DATA out=scores;
Answer: D
NEW QUESTION 14
Refer to the following odds ratio table:
What is a correct interpretation of the estimate?
- A. The odds of the event are 1.142 greater for each one dollar increase in salary.
- B. The odds of the event are 1.142 greater for each one thousand dollar increase in salary.
- C. The probability of the event is 1.142 greater for each one dollar increase in salary.
- D. The probability of the event is 1.142 greater for each one thousand dollar increase in salary.
Answer: B
NEW QUESTION 15
Which method is NOT an appropriate way to score new observations with a known target in a logistic regression model?
- A. Use the SCORE statement in the LOGISTIC procedure.
- B. Augment the training data set with new observations and set their responses to missing.
- C. Augment the training data set with new observations and rerun the LOGISTIC procedure.
- D. Use the saved parameter estimates from the LOGISTIC procedure and score new observations in the SCORE procedure.
Answer: C
NEW QUESTION 16
Including redundant input variables in a regression model can:
- A. Stabilize parameter estimates and increase the risk of overfitting.
- B. Destabilize parameter estimates and increase the risk of overfitting.
- C. Stabilize parameter estimates and decrease the risk of overfitting.
- D. Destabilize parameter estimates and decrease the risk of overfitting.
Answer: B
NEW QUESTION 17
When mean imputation is performed on data after the data is partitioned for honest assessment, what is the most appropriate method for handling the mean imputation?
- A. The sample means from the validation data set are applied to the training and test data sets.
- B. The sample means from the training data set are applied to the validation and test data sets.
- C. The sample means from the test data set are applied to the training and validation data sets.
- D. The sample means from each partition of the data are applied to their own partition.
Answer: B
NEW QUESTION 18
Refer to the exhibit: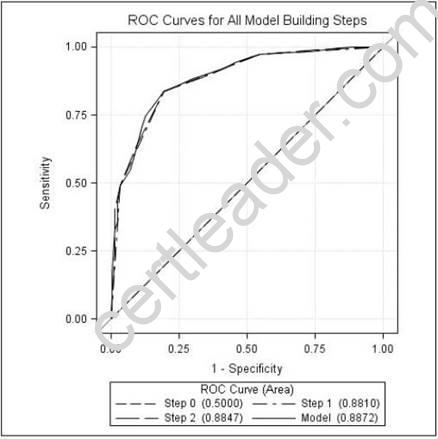
An analyst examined logistic regression models for predicting whether a customer would make a purchase. The ROC curve displayed summarizes the models. Using the selected model and the analyst's decision rule, 25% of the customers who did not make a purchase are incorrectly classified as purchasers.
What can be concluded from the graph?
- A. About 25% of the customers who did make a purchase are correctly classified as making a purchase.
- B. About 50% of the customers who did make a purchase are correctly classified as making a purchase.
- C. About 85% of the customers who did make a purchase are correctly classified as making a purchase.
- D. About 95% of the customers who did make a purchase are correctly classified as making a purchase.
Answer: C
NEW QUESTION 19
A company has branch offices in eight regions. Customers within each region are classified as either "High Value" or "Medium Value" and are coded using the variable name VALUE. In the last year, the total amount of purchases per customer is used as the response variable.
Suppose there is a significant interaction between REGION and VALUE. What can you conclude?
- A. More high value customers are found in some regions than others.
- B. The difference between average purchases for medium and high value customers depends on the region.
- C. Regions with higher average purchases have more high value customers.
- D. Regions with higher average purchases have more medium value customers.
Answer: B
NEW QUESTION 20
A predictive model uses a data set that has several variables with missing values. What two problems can arise with this model? (Choose two.)
- A. The model will likely be overfit.
- B. There will be a high rate of collinearity among input variables.
- C. Complete case analysis means that fewer observations will be used in the model building process.
- D. New cases with missing values on input variables cannot be scored without extra data processing.
Answer: CD
NEW QUESTION 21
Identify the correct SAS program for fitting a multiple linear regression model with dependent variable (y) and four predictor variables (x1-x4).
- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer: B
NEW QUESTION 22
An analyst fits a logistic regression model to predict whether or not a client will default on a loan. One of the predictors in the model is agent, and each agent serves 15-20 clients each. The model fails to converge. The analyst prints the summarized data, showing the number of defaulted loans per agent. See the partial output below: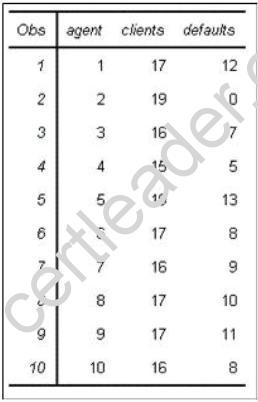
What is the most likely reason that the model fails to converge?
- A. There is quasi-complete separation in the data.
- B. There is collinearity among the predictors.
- C. There are missing values in the data.
- D. There are too many observations in the data.
Answer: A
NEW QUESTION 23
Refer to the lift chart: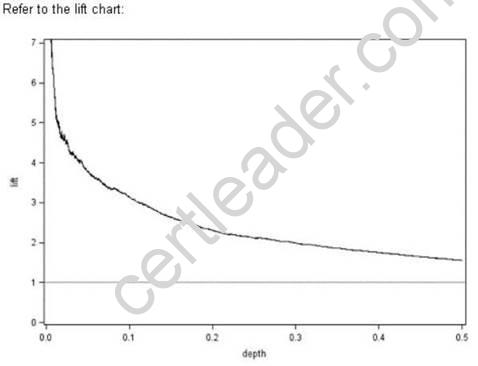
What does the reference line at lift = 1 corresponds to?
- A. The predicted lift for the best 50% of validation data cases
- B. The predicted lift if the entire population is scored as event cases
- C. The predicted lift if none of the population are scored as event cases
- D. The predicted lift if 50% of the population are randomly scored as event cases
Answer: B
NEW QUESTION 24
A non-contributing predictor variable (Pr > |t| =0.658) is added to an existing multiple linear regression model.
What will be the result?
- A. An increase in R-Square
- B. A decrease in R-Square
- C. A decrease in Mean Square Error
- D. No change in R-Square
Answer: A
NEW QUESTION 25
......
Thanks for reading the newest A00-240 exam dumps! We recommend you to try the PREMIUM Dumpscollection A00-240 dumps in VCE and PDF here: https://www.certshared.com/exam/{productsort}/ (65 Q&As Dumps)